AI Agent 的 LLM 知識庫與持久工作區比較

LLM 知識庫與持久工作區解決不同問題。了解哪種方式適合您的 AI Agent 工作流程,以及何時需要同時使用兩者。
在 AI Agent 的世界裡,「知識庫」這個詞被用來描述兩種截然不同的事物——把它們混為一談,會導致錯誤的架構選擇。
第一種是檢索系統:一組文件、嵌入向量或結構化資料,供 Agent 查詢以回答問題。想想 RAG 管線、向量資料庫、內部 Wiki。Agent 搜尋它、提取相關片段、放入上下文中使用。
第二種是專案記憶系統:記錄特定專案中發生的事——做過的決策、追蹤的進度、隨時間累積的脈絡。Agent 不像查資料庫那樣搜尋它,而是在 session 開始時載入,並在工作過程中回寫。
兩者都被稱為「知識庫」。它們解決的是完全不同的問題。選錯了,既浪費時間又會產出更差的結果。
傳統 LLM 知識庫的功能
傳統 LLM 知識庫是為大規模資訊檢索而建的。你有一個龐大的語料庫——文件、客服工單、產品規格、研究論文——你需要 Agent 按需找到相關資訊。
典型架構如下:
- 文件被切分並嵌入向量資料庫
- 查詢時,Agent 將查詢嵌入並檢索語義相似的片段
- 檢索到的片段被注入 prompt 作為上下文
- Agent 基於檢索內容生成回應
這就是 RAG(Retrieval-Augmented Generation,檢索增強生成)。它適合:
- 客服 Agent 從產品知識庫回答問題
- 研究助理搜尋大量文件集合
- 程式碼助理存取程式碼庫或 API 文件
- 企業內部 Wiki 和文件的跨域搜尋
關鍵特徵:知識庫是靜態或緩慢更新的。它儲存事實、文件和參考資料。Agent 從中讀取,但不會以有意義的方式回寫。
持久工作區的功能
持久工作區是為跨時間的專案連續性而建的。你在多個 session 中處理同一個專案——你需要 Agent 記住上次發生了什麼、做了什麼決策、目前進展到哪裡。
架構不同:
- Session 開始時,Agent 載入工作區(讀取當前狀態)
- Session 期間,Agent 執行工作
- Session 結束時(或過程中),Agent 回寫——記錄決策、更新狀態、儲存產出物
- 下一個 session 從更新後的狀態開始
這是一個讀寫循環。它適合:
- 自由工作者管理多個客戶專案
- 開發者在長期程式碼庫上工作
- 產品經理跨 sprint 追蹤功能
- 任何使用 AI Agent 進行多 session 工作流程的人
關鍵特徵:工作區是動態且專案範圍的。它儲存操作性脈絡——進度、決策、歷史——而非參考資料。而且它隨著每個 session 成長。
核心差異:參考記憶 vs. 操作記憶
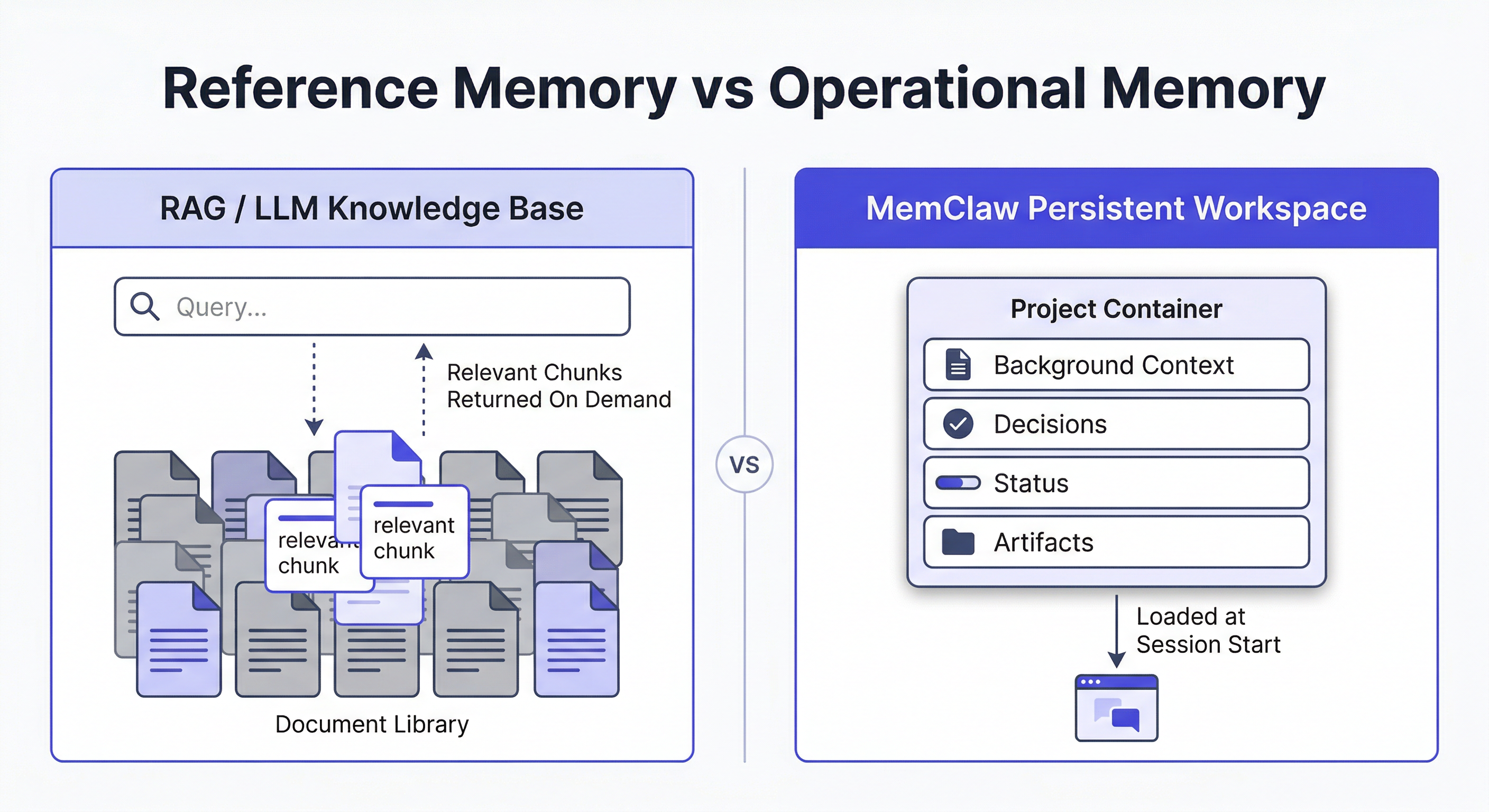
| LLM 知識庫 | 持久工作區 | |
|---|---|---|
| 儲存內容 | 事實、文件、參考資料 | 決策、進度、專案歷史 |
| Agent 使用方式 | 查詢 → 檢索 → 放入上下文 | 開始時載入 → 工作 → 回寫 |
| 更新頻率 | 不頻繁(批次更新) | 每個 session |
| 範圍 | 跨專案/使用者共享 | 限定於單一專案 |
| 主要用途 | 從語料庫回答問題 | 跨 session 延續工作 |
| 失敗模式 | 檢索錯誤片段、幻覺 | session 間脈絡遺失 |
兩者沒有優劣之分。它們解決不同的問題。混淆的原因是兩者都被稱為「知識庫」——而且很多團隊試圖用 RAG 系統解決專案連續性問題,或反過來。
何時需要 RAG 知識庫
在以下情況使用檢索式知識庫:
- 你有大量相對穩定的參考資料
- Agent 需要回答僅靠訓練資料無法回答的問題
- 多個使用者或 Agent 需要存取相同資訊
- 資訊是事實性和文件型的(非操作性的)
範例:
- 客服 Agent 需要從 500 頁產品文件中回答問題
- 法律助理搜尋判例法和合約
- 開發者 Agent 存取內部 API 規格
Agent 按需查詢知識庫。它不需要「記住」知識庫——它從中檢索。
何時需要持久工作區
在以下情況使用持久工作區:
- 你在多個 session 中處理特定專案
- Agent 需要知道前幾個 session 發生了什麼
- 你管理多個專案,需要彼此隔離
- 脈絡是操作性的——決策、狀態、歷史——而非參考資料
範例:
- 開發者 Agent 在數週內持續開發同一個程式碼庫
- 自由工作者的 Agent 同時管理 5 個客戶專案
- PM 的 Agent 追蹤一個功能從規格到上線
Agent 在 session 開始時載入工作區。它不搜尋工作區——它讀取當前狀態,從上次中斷的地方繼續。
何時兩者都需要
許多真實工作流程兩者都需要——而且它們扮演不同角色。
以一個在客戶專案上工作的開發者 Agent 為例:
- RAG 知識庫:程式碼庫、API 文件、內部風格指南——Agent 需要查找時使用的參考資料
- 持久工作區:專案歷史——已建構的內容、做過的決策、這個 sprint 正在進行的工作
知識庫回答「這個 API endpoint 做什麼?」工作區回答「上週二我們做到哪裡了?auth flow 我們決定怎麼做?」
它們是互補的,不是競爭的。
多專案問題:RAG 的不足之處
這是實務中差異最重要的地方。
如果你用 AI Agent 同時跑多個專案,共享的 RAG 知識庫會產生一個問題:脈絡串台。客戶 A 的文件和客戶 B 的在同一個向量資料庫裡。Agent 從兩邊都檢索。為一個專案做的決策出現在另一個專案中。
你可以嘗試用 metadata 過濾來解決——為每份文件標記專案 ID,查詢時過濾。可以用,但很脆弱,需要仔細維護。
持久工作區用不同方式解決:每個專案是完全隔離的環境。載入 Project A 的工作區,Agent 只有 Project A 的脈絡。不需要過濾,因為隔離是結構性的。
這就是為什麼專案範圍的工作區比共享知識庫——即使是組織良好的——更適合處理多專案工作流程。
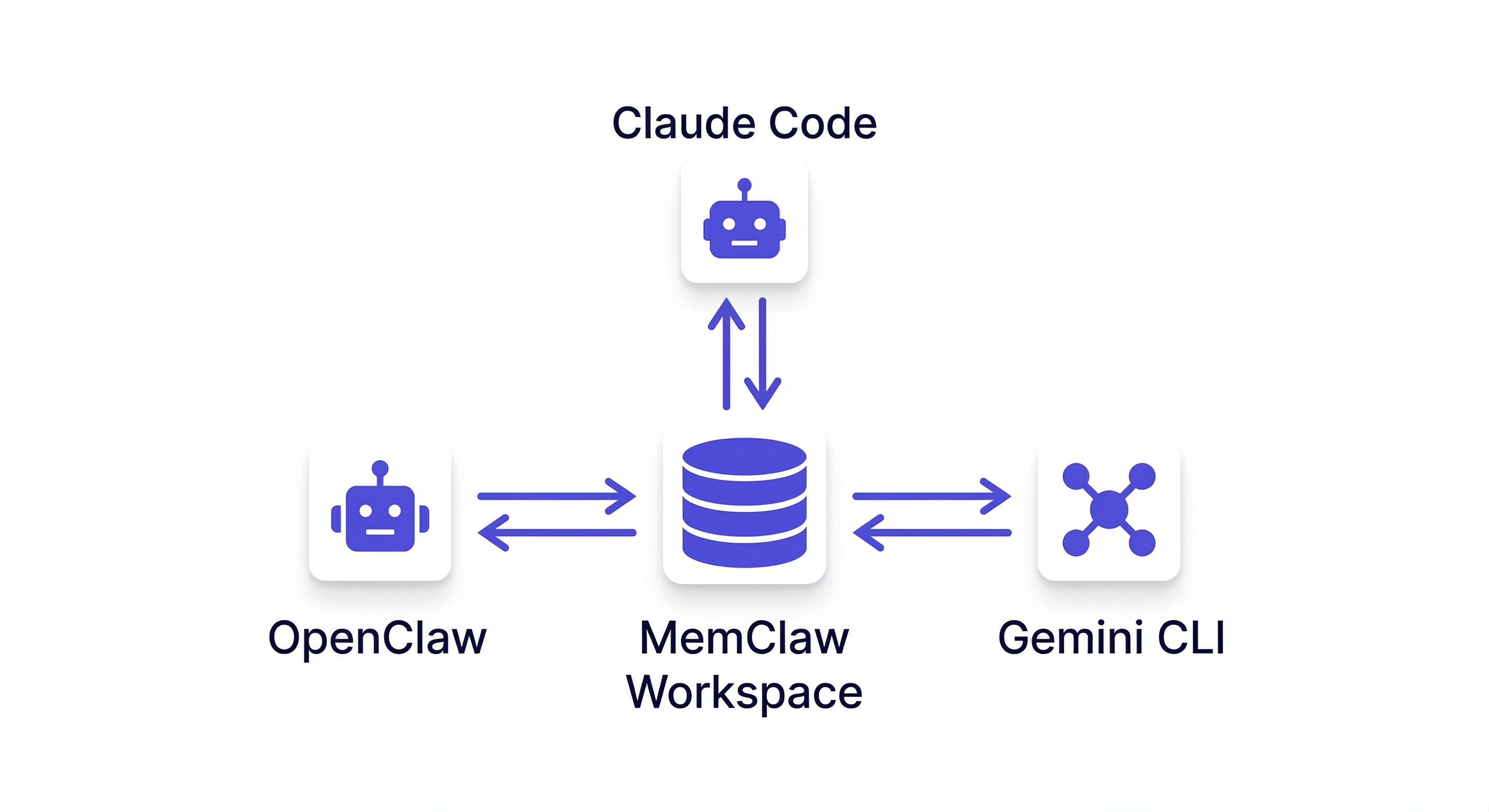
MemClaw 如何為 OpenClaw 實現持久工作區
MemClaw 專門為持久工作區的使用場景而建——為管理多個專案的 OpenClaw 和 Claude Code 使用者提供專案連續性。
每個工作區儲存:
- Living README — 背景脈絡、偏好設定、當前進度、關鍵決策
- 產出物 — 專案期間產生的文件、報告、URL、檔案
- 任務 — Agent 工作時自動追蹤
- 決策日誌 — 架構選擇、已同意的方案、已結案的問題
Agent 在 session 開始時讀取(8 秒脈絡恢復),工作過程中回寫。無需手動維護。無需重新簡報。
安裝方式:
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
設定 API key:
export FELO_API_KEY="your-api-key-here"
在 felo.ai/settings/api-keys 取得你的 key。
然後為每個專案建立工作區:
Create a workspace called Project Alpha
這就是全部設定。不需要 JSON 設定檔、不需要向量資料庫、不需要嵌入管線。
選擇正確的架構
快速決策框架:
選 RAG 知識庫如果:
- 你有大量文件語料庫需要搜尋
- Agent 需要按需取得事實性參考資料
- 多個 Agent 或使用者共享相同資訊
選持久工作區如果:
- 你在多個 session 中處理特定專案
- Agent 需要記住上次發生了什麼
- 你管理多個專案,需要隔離
兩者都選如果:
- 你有 Agent 需要查詢的參考資料(RAG)
- 而且你在做跨多個 session 的持續專案(工作區)
大多數認真的 AI Agent 工作流程最終都需要兩者。錯誤在於試圖用一個來做另一個的工作。
為什麼「用更大的 Context Window」解決不了這個問題
面對記憶問題,常見的回應是:把所有東西都放進 context window。有了長上下文模型,這似乎可行。但它無法擴展,原因如下。
成本:每個 session 都把所有專案歷史和文件載入上下文,成本很高。大部分內容與當前任務無關。
雜訊:塞滿可能無關資料的大 context window 會降低回應品質。模型會關注上下文中的所有內容,包括現在不重要的東西。
多專案隔離:共享的 context window 無法在專案間隔離。所有東西同時可見——這正是脈絡串台問題。
操作記憶 vs. 參考記憶:即使有無限的 context,你仍然需要區分參考資料(要查詢的文件)和操作記憶(要維護的專案狀態)。它們服務不同目的,受益於不同架構。
持久工作區不是有限 context 的權宜之計。無論 context window 多大,它都是操作性專案記憶的正確架構。
實際範例:同一個 Agent,兩種不同的記憶需求
以一位使用 OpenClaw 管理 SaaS 產品上線的產品經理為例。
她同時有兩種截然不同的記憶需求。
需求 1:參考資料 Agent 需要存取產品規格、競品研究、使用者訪談逐字稿,以及工程團隊的技術限制。這是參考資料——量大、相對穩定、按需查詢。
RAG 知識庫很適合處理這個。她將文件索引化,Agent 在回答「使用者對 onboarding 流程說了什麼?」或「通知系統的技術限制是什麼?」時檢索相關段落。
需求 2:專案記憶 Agent 需要知道上線日期從三月延到四月了、定價團隊否決了原本的免費方案決策、Salesforce 整合被降級到 v2、上個 session 結束時 email 行銷文案寫到一半。
RAG 知識庫處理這個很差。這些不是要檢索的文件——它們是特定專案當前狀態的操作性事實。它們頻繁變動。需要在 session 開始時完整載入,而非透過相似度搜尋檢索。
持久工作區很適合處理這個。
她最終兩者都用:RAG 系統處理文件語料庫,MemClaw 處理專案狀態。各司其職。
常見問題
MemClaw 可以和 RAG 系統一起使用嗎? 可以。MemClaw 處理專案記憶(工作區)。你的 RAG 系統處理文件檢索。兩者獨立運作,互相補充。
MemClaw 使用向量嵌入嗎? 不。MemClaw 儲存結構化的專案脈絡——決策、狀態、產出物——而非文件嵌入。它不是檢索系統;它是專案記憶系統。
如果我的專案既有參考文件又有持續性工作怎麼辦? 兩者都用。參考文件存在 RAG 系統中。專案歷史和決策存在 MemClaw 工作區中。各司其職。
MemClaw 除了 OpenClaw 也支援 Claude Code 嗎? 是的。MemClaw 支援 OpenClaw、Claude Code、Gemini CLI 和 Codex——全部共享同一個工作區。