如何在 OpenClaw 中設定持久記憶(完整教學)

一步步教你在 OpenClaw 中設定持久記憶。安裝 MemClaw、建立工作區、跨對話保留專案上下文,不再每次從零開始。
你已經在一個客戶專案上工作了三週。OpenClaw 知道技術棧、API 的眉角、你偏好的命名慣例。然後你關掉了終端機。
隔天早上,你開了一個新對話。OpenClaw 完全不知道你的客戶是誰。
這就是 OpenClaw 預設處理記憶的方式:所有東西都活在對話裡。對話結束,上下文就消失了。如果你只做一個專案,這很煩。如果你同時跑五個,這就是真正的問題。
這篇指南教你如何在 OpenClaw 中設定持久記憶——跨對話、跨天數、跨代理都能保留的記憶——讓你的專案真正停在你離開的地方。
OpenClaw 的記憶運作方式(預設)
OpenClaw 使用對話式記憶模型。在一次對話中,它記得所有東西:你的指示、討論過的檔案、做過的決策。但那些記憶綁定在當前對話上。
實際上這意味著:
- 開始對話 — OpenClaw 對你的專案零認知
- 工作一小時 — OpenClaw 建立起對你工作的豐富理解
- 結束對話 — 所有理解消失
- 開始新對話 — 回到原點
對一次性任務來說沒問題。請 OpenClaw 寫個腳本、修個 bug、產生報告——搞定。不需要記憶。
但如果你把 OpenClaw 當作跨多個專案的長期工作夥伴,對話記憶就不夠了。你會不斷重複自己:
「記住,這個專案用 PostgreSQL,不是 MySQL。」 「我們上週決定用 JWT 認證。」 「客戶偏好條列式而不是長段落。」
這不是生產力。這是在帶小孩。
對話記憶 vs. 持久記憶
差別很直接:
| 對話記憶 | 持久記憶 | |
|---|---|---|
| 持續時間 | 到你關閉對話為止 | 跨對話、跨天、跨週 |
| 範圍 | 單次對話 | 整個專案生命週期 |
| 儲存內容 | 聊天記錄 | 決策、偏好、進度、文件 |
| 多專案 | 沒有隔離——全部混在一起 | 每個專案有自己的記憶 |
| 設定 | 內建(不需設定) | 需要記憶工具 |
對話記憶像是每晚擦掉的白板。持久記憶像是放在桌上的專案筆記本。
為什麼 OpenClaw 沒有內建持久記憶
OpenClaw 被設計為通用 AI 代理。它連接工具(skills)、遵循指示、產生輸出。但它沒有內建的方式來跨對話儲存和回憶專案特定的上下文。
這有合理的原因:
- 隱私 — 持久儲存意味著你的資料存在某處。這是設計決策,不是預設值。
- 範圍 — 不同使用者需要儲存不同的東西。開發者的「記憶」和業務人員的完全不同。
- 彈性 — 把記憶作為附加功能,你可以選擇適合工作流程的工具。
這就是第三方記憶工具的用武之地。最常見的方式是安裝一個處理儲存和擷取的記憶 skill。
用 MemClaw 設定持久記憶
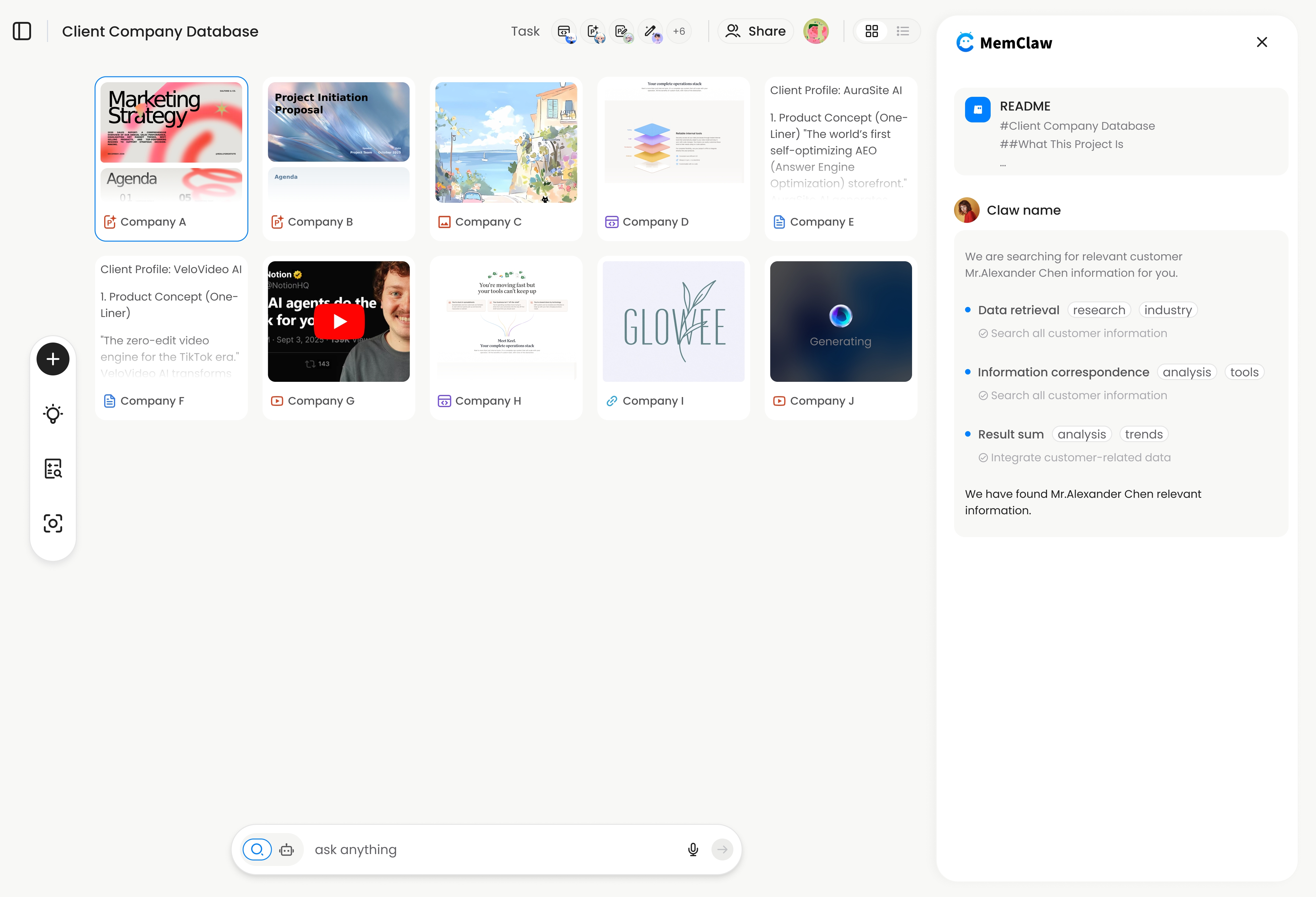
MemClaw 是專為 OpenClaw 和 Claude Code 打造的持久工作區工具。它為每個專案提供獨立的隔離工作區——包含動態 README、產出物和自動追蹤的任務——AI 在每次對話開始時載入。
以下是從頭到尾的完整設定。
步驟一:取得 API Key
MemClaw 使用 Felo API 進行儲存。你需要一個 API key(免費開始):
- 前往 felo.ai/settings/api-keys
- 建立新的 API key
- 複製到安全的地方
設定為環境變數:
# macOS / Linux
export FELO_API_KEY="your-api-key-here"
# Windows PowerShell
$env:FELO_API_KEY="your-api-key-here"
要讓它在終端機對話間持續有效,把 export 那行加到你的 ~/.zshrc 或 ~/.bashrc。
步驟二:安裝 MemClaw
選擇符合你設定的方式:
選項 A:OpenClaw 安裝腳本(推薦)
bash <(curl -s https://raw.githubusercontent.com/Felo-Inc/memclaw/main/scripts/openclaw-install.sh)
選項 B:自然語言安裝
直接傳送這則訊息給 OpenClaw:
「請安裝 https://github.com/Felo-Inc/memclaw 並在安裝後使用 MemClaw。」
OpenClaw 會 clone 儲存庫並設定為 skill。
選項 C:手動安裝
git clone https://github.com/Felo-Inc/memclaw.git
# 複製到你的代理 skill 目錄:
cp -r memclaw/memclaw ~/.claude/skills/ # Claude Code
# 或:cp -r memclaw/memclaw ~/.gemini/skills/ # Gemini CLI
# 或:cp -r memclaw/memclaw ~/.codex/skills/ # Codex
步驟三:建立第一個工作區
MemClaw 安裝完成後,直接告訴 OpenClaw:
「建立一個叫做 Client Acme 的工作區」
就這樣。MemClaw 為 Acme 專案建立一個隔離的工作區。它儲存:
- 動態 README — 背景、偏好、當前進度
- 產出物 — 對話中產生的文件、報告、網址、檔案
- 任務 — AI 工作時自動追蹤
不需要 JSON 設定。不需要編輯檔案。全程自然語言。
步驟四:載入工作區
下次對話,當你想繼續 Acme 專案時:
「載入 Acme 工作區」
MemClaw 在大約 8 秒內恢復完整的專案上下文。OpenClaw 立刻知道:
- 專案是關於什麼的
- 做了哪些決策
- 目前在進行什麼
- 還有什麼需要做
不用重新簡報。不用「記住,我們用 PostgreSQL」。AI 直接接續上次的進度。
步驟五:工作時保存上下文
工作時,你可以明確保存重要決策:
「加到工作區:我們決定用 Stripe 付款,因為客戶已經有 Stripe 帳號」
「把那份競品分析保存到工作區」
MemClaw 的代理也會在自然對話中自動捕捉上下文,所以你不需要手動保存所有東西。
管理多個專案
這是持久記憶最能改變工作流程的地方。不再是一個長對話把所有東西混在一起,而是乾淨的分離:
工作區:Client Acme → API 重新設計,偏好 REST,2 週時程
工作區:Client Beta → 電商網站,Shopify 整合,預算考量
工作區:Internal Tool → 管理後台,React + TypeScript,技術債清單
自然地切換:
「載入 Beta 工作區」
OpenClaw 立刻切換上下文。Acme 的 API 重新設計不會滲入 Beta 的電商專案。每個工作區都是隔離的。
實際工作流程範例
一位自由接案的開發者管理三個活躍客戶:
週一早上:
「載入 Acme 工作區」 「我們付款整合做到哪了?」
OpenClaw 回應當前狀態——Stripe webhook handler 做了一半,還有一個關於重試邏輯的未決問題。
週一下午:
「載入 Beta 工作區」 「客戶批准了產品頁面的 mockup。我們開始做吧。」
OpenClaw 已經知道技術棧(Next.js + Shopify)、客戶偏好極簡設計、以及具體的產品分類。
週二:
「載入 internal tool 工作區」 「給我看我們一直在追蹤的技術債項目」
OpenClaw 列出之前對話的項目,附帶優先級和備註。
沒有上下文混淆。不用重新解釋。三個專案,三個隔離的記憶。
持久記憶儲存什麼
MemClaw 工作區儲存幾種類型的資訊:
動態 README
每個工作區的核心。一份結構化文件,捕捉:
- 專案背景和目標
- 你的偏好(程式碼風格、溝通偏好、工具選擇)
- 當前進度和狀態
- 關鍵決策及其背後的理由
README 隨著你的工作更新。你也可以明確更新:
「更新工作區:客戶把截止日期改到 4 月 20 日」
產出物
對話中產生的任何你想保留的東西:
- 研究報告
- 會議摘要
- 程式碼架構決策
- 競品分析
- 網址和參考資料
自然地保存:
「把那份報告保存到工作區」
之後擷取:
「找到我們上週做的定價分析」
任務
AI 工作時自動追蹤。如果你說「我們來給儀表板加深色模式」,MemClaw 會記錄為任務。隨時查看任務清單:
「顯示工作區任務」
跨代理記憶:OpenClaw + Claude Code
對開發者來說很重要的功能:MemClaw 在 OpenClaw 和 Claude Code 之間都能使用。如果你在 OpenClaw 做研究,然後切換到 Claude Code 實作,兩個代理讀取同一個工作區。
支援的代理:
- OpenClaw
- Claude Code
- Gemini CLI
- Codex
為每個代理安裝 MemClaw 到對應的 skill 目錄:
| 代理 | Skill 目錄 |
|---|---|
| Claude Code | ~/.claude/skills/ |
| Gemini CLI | ~/.gemini/skills/ |
| Codex | ~/.codex/skills/ |
工作區資料透過 Felo API 儲存,所以與代理無關。同一個工作區,同一份記憶,不管你用哪個代理。
持久記憶 vs. 其他方案
你可能在想:我不能直接用 CLAUDE.md 或手動貼上下文嗎?以下是持久記憶和常見替代方案的比較:
手動貼上下文
每次對話開始時複製貼上你的專案筆記。小專案可以。當你有 5 個以上不同上下文的專案,筆記檔案長到 3,000 字時就崩潰了。
CLAUDE.md / 系統指示
適合靜態偏好(「永遠用 TypeScript」、「偏好函數式元件」)。不適合動態專案狀態——什麼在進行中、昨天決定了什麼、客戶今天早上說了什麼。
Mem0
AI 代理的記憶層,儲存對話片段。和 MemClaw 方式不同:Mem0 儲存個別記憶(事實、偏好),MemClaw 儲存專案範圍的工作區(每個專案的完整上下文)。如果你需要多個同時進行的專案之間的隔離,基於工作區的記憶更適合。
完全沒有記憶
有些人每次對話都重新解釋所有東西。在某個時間點之前可以。如果你每次對話的前 10 分鐘都在重新簡報 AI 代理,你每週損失好幾個小時。
常見設定問題排除
「找不到 MemClaw skill」
確認 skill 檔案在正確的目錄。檢查你的代理的 skill 資料夾:
ls ~/.claude/skills/memclaw/ # Claude Code
ls ~/.gemini/skills/memclaw/ # Gemini CLI
ls ~/.codex/skills/memclaw/ # Codex
你應該看到 MemClaw 的 skill 檔案。如果沒有,重新執行安裝。對 OpenClaw,安裝腳本(選項 A)會自動處理放置。
「API key 未設定」
驗證你的環境變數:
echo $FELO_API_KEY
如果是空的,重新設定並確認它在你的 shell 設定檔(.zshrc 或 .bashrc)中。
「工作區無法載入」
確認你使用的是建立時的確切工作區名稱:
「列出我所有的專案」
這會顯示所有工作區及其名稱。
上下文似乎過時
動態 README 會自動更新,但你可以強制更新:
「用我們目前的進度更新工作區」
開始使用
在 OpenClaw 中設定持久記憶大約需要 2 分鐘:
- 在 felo.ai/settings/api-keys 取得 API key
- 用一個指令安裝 MemClaw
- 建立第一個工作區:「建立一個叫做 [專案名稱] 的工作區」
從那時起,每次對話都帶著上下文開始——不再從零開始。
如果你在 OpenClaw 中管理多個專案,每次對話都花時間重新解釋上下文,持久記憶不是可選的。它是一個會忘記的 AI 助手和一個真正跟得上的 AI 助手之間的差別。
在 memclaw.me 免費開始使用
MemClaw 可在 GitHub 上取得。查看程式碼:github.com/Felo-Inc/memclaw。