持久化 AI 記憶:讓 AI 真正記住一切的完整指南

AI 助手在工作階段結束後就會忘記一切。了解持久化 AI 記憶的運作原理、不同的實作方式,以及如何在實際開發工作中落地應用。
目前最強大的 AI 程式碼助手都有一個根本限制:工作階段結束後就會忘記一切。
Claude Code、OpenClaw、Gemini CLI——全部都是每次工作階段從零開始。不知道你的程式碼庫。不記得上週做的決策。沒有你已經嘗試過並排除的方案記錄。
本指南涵蓋持久化 AI 記憶的運作原理、可用的方法,以及如何在實務中實作。
為什麼 AI 助手預設不會記憶
AI 語言模型是無狀態的。每次工作階段都是一次獨立的運算——模型處理你的輸入並產生回覆,但該互動的任何內容都不會儲存在模型本身中。
這是刻意的設計選擇。無狀態系統:
- 更容易建構和維護
- 行為更可預測
- 更容易擴展
- 更安全(不會累積錯誤資訊)
對於一般使用,無狀態沒問題。但對於持續性工作——開發專案、產品管理、研究——它會造成顯著的摩擦。你變成了 AI 的外部記憶體,每次工作階段都手動重新載入上下文。
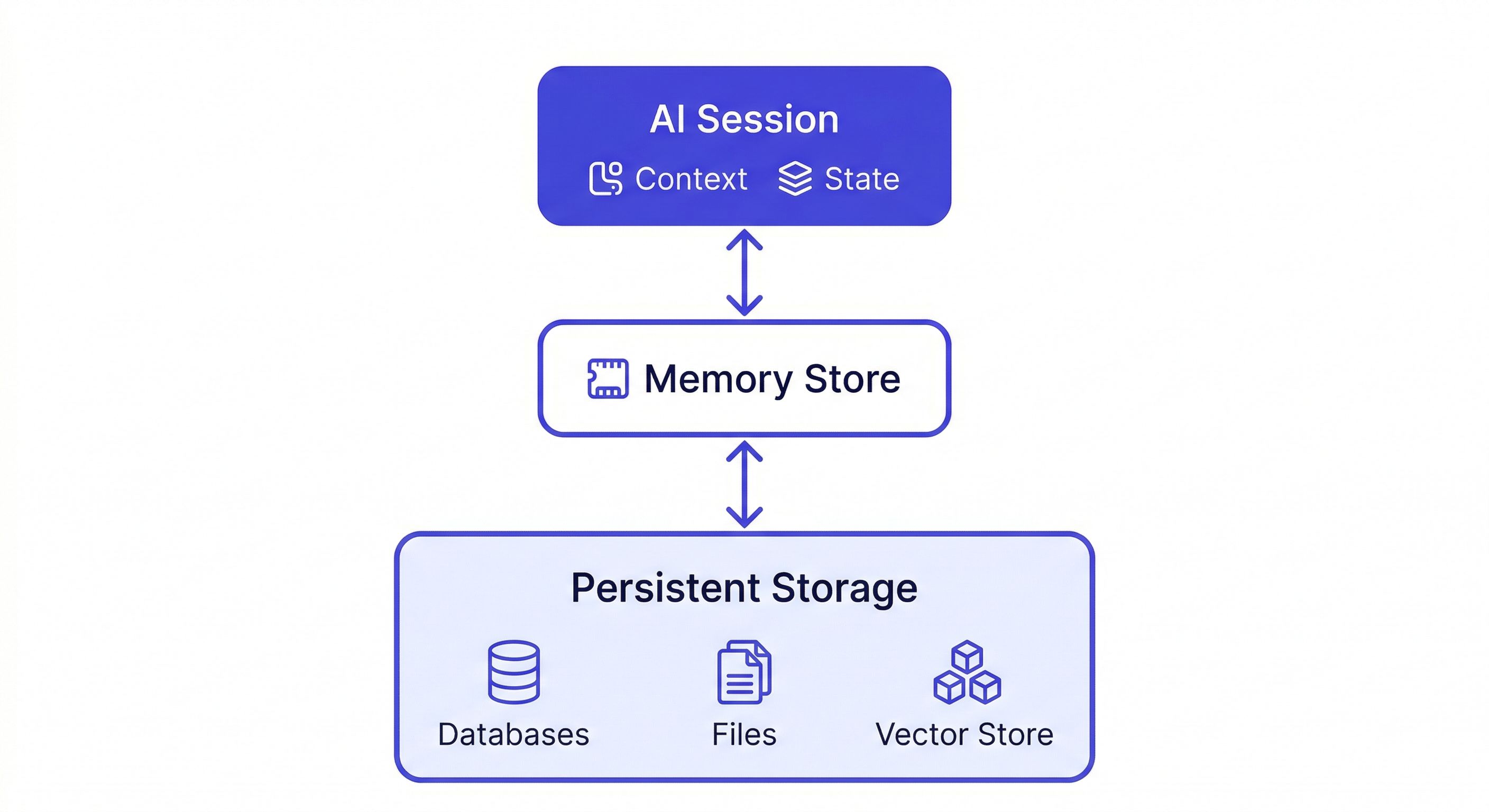
持久化記憶需要儲存什麼
並非所有上下文都同樣值得持久化。值得儲存的內容:
附帶理由的決策 ——不只是「我們用 Postgres」,而是「我們用 Postgres 是因為客戶的 DBA 只支援它,而且這個限制不會改變。」理由才是防止 AI 在未來工作階段中用有說服力的反論重新提出這個問題的關鍵。
已排除的方案 ——這一點被嚴重低估了。「我們在 webhook 處理器中嘗試了 Redis 快取,結果造成了競態條件」可以防止 AI 再次建議 Redis。沒有這個記錄,你會反覆探索已經走過的死路。
當前狀態 ——目前事情進展到哪裡。什麼正在進行中、什麼已完成、什麼被阻塞。這是 AI 在恢復工作時最先讀取的內容。
產出物 ——AI 產生的文件、分析、規格、URL。將它們放在工作區中意味著你可以在未來的工作階段中引用它們,而不需要重新產生。
持久化記憶的方法
1. 基於檔案(CLAUDE.md)
在專案根目錄放一個 markdown 檔案,Claude 在工作階段開始時讀取:
# MyApp
Stack: Next.js 14, TypeScript, PostgreSQL
Auth: JWT in httpOnly cookies (security team requirement)
Known issue: Stripe webhook fires twice — always check idempotency key
Current status: Refactoring auth middleware
優點: 零設定、版本控制、離線可用、無外部依賴。
缺點: 靜態——你需要手動維護,它會逐漸過時。沒有對話歷史。每個專案只有一個扁平檔案。無法搜尋。無法跨專案管理。
最適合: 單一小型專案、獨立開發者、短期專案。
2. 基於工作區(MemClaw)
每個專案一個結構化的持久化工作區,作為技能連接到你的 AI 代理。
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
工作區儲存決策、狀態、產出物和背景上下文。代理在工作階段開始時讀取它,並在你工作時寫回更新。
優點: 持久化且可搜尋。隨著你的工作自動累積。專案隔離(每個專案有自己的工作區)。團隊共享。跨代理相容(Claude Code、OpenClaw、Gemini CLI 都讀取同一個工作區)。
缺點: 需要 Felo API 金鑰。需要網路連線。
最適合: 多個專案、持續性工作、團隊協作。
3. 自行建構
使用向量資料庫建構你自己的持久化記憶層,並連接到你的 AI 代理。
優點: 完全控制。自行託管。可自訂儲存和檢索邏輯。
缺點: 顯著的工程開銷。維護負擔。你在解決一個已經被解決的問題。
最適合: 有特定資料主權要求或自訂記憶需求的組織。
什麼讓持久化記憶真正有用
擁有持久化記憶是必要的但不充分的。三個原則決定它是否真正隨時間複利成長:
儲存決策時附帶理由。 「使用 Postgres」遠不如「使用 Postgres 是因為客戶的 DBA 只支援 Postgres,而且我們無法改變這一點」有用。理由才是給 AI 完整上下文以在未來工作階段中做出一致決策的關鍵。
儲存已排除的方案。 每次你嘗試了某個不可行的方案,就記錄下來。「我們嘗試了方案 X——因為 Y 而失敗」可以防止 AI 在未來的工作階段中推薦同樣的方案。沒有這個記錄,你會反覆探索死路。
持續維護。 一個在 70% 的工作階段中更新、30% 被忽略的記憶庫,不如一個每次工作階段都更新的記憶庫可靠。先建立習慣,然後讓它複利成長。
讀寫循環
讓持久化記憶真正有用的模式是讀寫循環:
- 工作階段開始: 載入工作區——AI 讀取當前上下文
- 工作階段期間: 進行工作、做出決策
- 工作階段結束: 寫回——記錄做出的決策、更新狀態、儲存產出物
每次工作階段都增加一些內容。知識庫不斷複利成長。幾週後,AI 開始從工作區回答問題,而不是要求你重新解釋。幾個月後,你擁有了一份可搜尋的專案完整記錄。
Load the MyApp workspace
[work happens]
Add decision to workspace: using server-side rendering for the dashboard —
client requires SEO indexability, CSR doesn't meet that requirement
Update workspace status: dashboard pages migrated to SSR, API routes next
這就是習慣。每次工作階段只需 30 秒。複利效果立即開始。
團隊的持久化記憶
當團隊共享一個 MemClaw 工作區時:
- 每位開發者的 AI 工作階段都從同一個專案知識庫中提取資訊
- 一位開發者做出的架構決策立即對所有其他人可用
- 新團隊成員載入工作區就能立即獲得專案上下文
- 程式碼審查可以自動引用共享的慣例
工作區成為專案上下文的唯一真實來源——不是一份沒人看的 Notion 文件,而是每次 AI 工作階段都會自動讀取的活躍記憶層。
開始使用
在 Claude Code 上安裝 MemClaw:
/plugin marketplace add Felo-Inc/memclaw
/plugin install memclaw@memclaw
export FELO_API_KEY="your-api-key-here"
為每個專案建立一個工作區:
Create a workspace called [Project Name]
每次工作階段開始時載入:
Load the [Project Name] workspace
建立寫回習慣:
Add decision to workspace: [decision + reasoning]
Update workspace status: [current state]
Save that analysis to the workspace
從基礎開始,讓它自然成長。記憶從第一次工作階段就開始複利累積。