在 Felo LLM Playground 免費試用 DeepSeek V4

Felo LLM Playground 在發佈當天加入了 DeepSeek V4-Pro 與 V4-Flash。與兆級參數的開源模型免費對話——無需 API 金鑰。
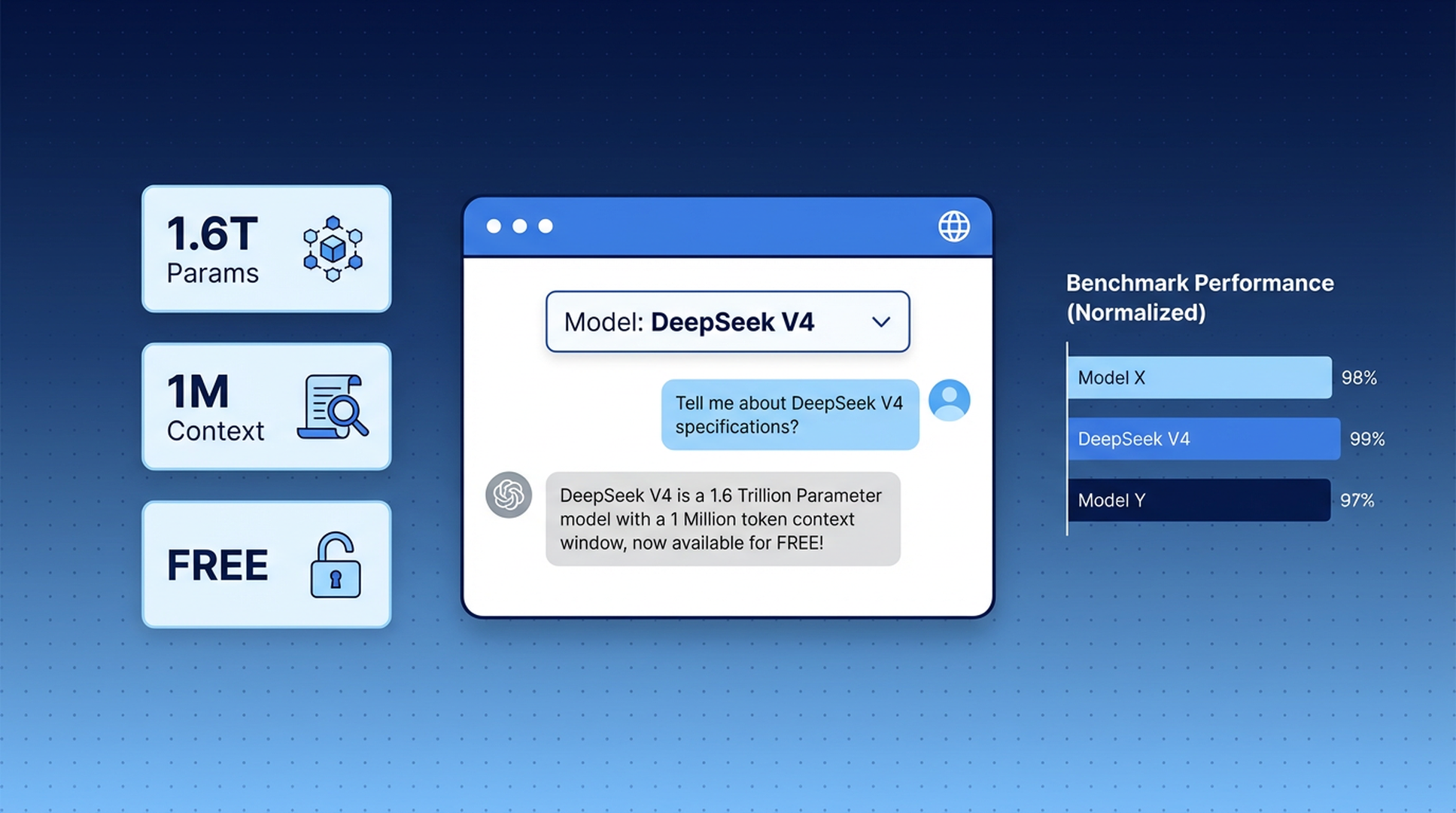
DeepSeek V4 本週正式推出——這是一款擁有兆級參數的開源模型,在多數基準測試中可與 GPT-5.4 和 Claude Opus 4.6 媲美。它是迄今為止最強大的開源權重模型。
你現在就可以在 Felo LLM Playground 上免費與它對話。無需 API 金鑰、無需額度、無需帳號。只要選擇模型就能開始聊天。
什麼是 Felo LLM Playground?
Felo LLM Playground 是一個免費、基於瀏覽器的聊天介面,你可以在這裡與全球頂尖的 AI 模型並排互動。可以把它想像成 LLM 的試驗廚房——你提出問題,並選擇要由哪個模型回答。
Playground 目前支援來自 OpenAI、Anthropic、Google 以及現在的 DeepSeek 模型。你可以在對話中隨時切換模型、比較回應,並找出最適合你任務需求的模型——無需註冊不同的 API 帳號或管理帳單。
它專為任何想無障礙體驗最新模型的人而設計。包括評估模型的開發者、比較推理品質的研究人員、需要強大 AI 助手但不想每月為每個服務支付 20 美元的學生,或是單純好奇兆級參數模型實際使用感的使用者。
DeepSeek V4:您將能獲得的功能
DeepSeek V4 提供兩個版本,兩者皆可在 Playground 上使用:
DeepSeek V4-Pro 是完整版本模型。共有 1.6 兆個參數,每次查詢啟用 490 億個參數,並以 32 兆個語料進行訓練。它在處理複雜推理、程式編寫、數學以及長文件分析方面的表現,能與目前最佳的封閉模型直接競爭。
DeepSeek V4-Flash 是快速版本。共有 2,840 億個參數,每次查詢啟用 130 億個。它能在不需要大型模型延遲的情況下,快速且精確地回應日常問題。
兩個版本皆具備一百萬個 token 的上下文視窗——足以在單次對話中處理整個程式碼庫、一本文長的文件,或數月的會議記錄。
性能比較
以下是 V4-Pro 與現今主要模型的表現比較:
| 基準測試 | DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| MMLU | 90.1% | 約 91% | 約 89% |
| HumanEval | 76.8% | 約 78% | 約 77% |
| SWE-bench Verified | 80.6% | 約 82% | 約 80% |
| Codeforces 評分 | 3,206 | 約 3,100 | 約 2,900 |
| MATH | 64.5% | 約 66% | 約 63% |
V4-Pro 在競賽程式設計中領先,並在數項編碼任務上與 GPT-5.4 不相上下或更勝一籌。其延伸推理模式(V4-Pro-Max)在 LiveCodeBench 中取得 93.5% 的分數,在 IMOAnswerBench 中則達到 89.8%。
開源與封閉模型之間的差距從未如此之小。在某些任務上,這個差距甚至完全消失了。
如何在 Playground 上使用 DeepSeek V4
這大約只需要五秒鐘:
1. 開啟 Playground。
在瀏覽器中前往 playground.felo.ai,不需要登入。
2. 從模型選單中選擇 DeepSeek V4。
你會看到一個包含所有可用模型的下拉選單。針對複雜任務選擇 V4-Pro,或選擇 V4-Flash 以獲得快速回覆。
3. 開始聊天。
自然地輸入你的問題。模型會即時回應,就像你以往使用的任何聊天介面一樣。
這就是整個設定。無需設定 API 金鑰、沒有權杖配額,也沒有帳單頁面。
值得嘗試的幾件事
如果你不確定從哪開始,以下是一些能展示 V4 功能的提示:
- 貼上一份長的程式碼檔,請 V4-Pro 尋找錯誤或提出重構建議
- 給它一道數學題——如果想挑戰極限,可以用競賽等級的題目
- 請它以特定方式解釋技術概念(「像我是一位資料庫工程師那樣解釋 transformers」)
- 放上一篇研究論文摘要,請它進行批判性分析
- 在 V4-Pro 和 GPT-5.4 上使用相同的提示並排比較——Playground 讓這件事變得很簡單
何時該選擇 V4-Pro 與 V4-Flash
兩個模型都可在 Playground 中使用,選擇其實相當簡單。
V4-Pro 適用於困難的問題,例如研究整合、除錯複雜程式碼、數學證明、長文件分析,或任何需要深入推理的任務。它速度較慢,但思考更深入。
V4-Flash 則適用於其他所有情境,如快速查詢事實、撰寫草稿、腦力激盪、翻譯或摘要。它回應更快,並能與大型模型一樣出色地處理日常任務。如果你在一次對話中要提很多問題,V4-Flash 能讓進程更順暢。
一個簡單的經驗法則是:先從 V4-Flash 開始。如果答案顯得淺顯,或任務明顯較複雜,再切換到 V4-Pro。Playground 允許你在對話中途更換模型,因此可以放心嘗試。
為什麼 Playground 對於嘗試新模型很重要
每次有新模型推出,都會出現同樣的問題:要怎麼實際體驗它?
官方 API 需要註冊帳號、綁定信用卡、撰寫程式碼發送請求,並管理 Token 成本。若你要將模型整合進產品,那沒問題;但如果只是想問幾個問題、看看它怎麼思考,就太麻煩了。
Felo LLM Playground 讓整個流程變得極為簡單。新模型發布時,只要打開瀏覽器分頁,你就能開始使用。不需要設定、沒有費用、也不需任何承諾。
這件事情的重要性超乎想像。「我應該試試那個新模型」與「實際去試」之間的差距,通常是 20 分鐘的帳號設定與 API 配置。Playground 讓這個過程降為零。
它也讓模型比較變得實用。想知道 DeepSeek V4 是否比 Claude 或 GPT 更適合你的使用情境嗎?只要在相鄰的分頁中向每個模型提出相同的問題即可。五分鐘的實際測試,比你閱讀基準測試表還能學到更多。
為什麼值得嘗試 DeepSeek V4
除了基準分數之外,V4 還有一些實際體驗起來相當有趣的特點:
三種推理模式。 V4 提供非思考(快速、直接回答)、高階思考(逐步分析)與極限思考(最大推理努力)。你真的能感受到差異——在困難的數學問題上,極限思考模式會產生明顯更完整的結果。在 Playground 上,這表示你可以調整模型投入在問題上的運算量。簡單的事實查核不需要極限思考,有挑戰性的證明則需要。
強大的多語言表現。 V4 的訓練大幅強調多語言資料。如果你在多種語言間工作——英文與中文、日文與韓文,或任何組合——V4 能很好地處理語碼轉換與跨語言問題。你可以用英文詢問一個中文資料來源,它也能毫不遲疑地回應。
程式設計能力。 以 Codeforces 評級 3,206 與 SWE-bench 成績 80.6% 而言,V4-Pro 是目前你能使用的最強大編碼模型之一。請它撰寫函式、審查 pull request,或解釋為什麼你的正則表達式沒有匹配——它的表現一貫穩定。Playground 是快速測試的方式:貼上一段程式碼,請它審查,然後將 V4 的回饋與 Claude 或 GPT 比較。
百萬 Token 的上下文。 大多數模型的上限是 128K 或 200K tokens,而 V4 可處理一百萬。那大約相當於 75 萬個單詞——約 10 本長篇小說,或一家中型公司的整套內部文件。你可以貼上整個專案的程式碼庫,直接針對內容提問,而不需要先分塊或摘要。以往模型必須將工作拆分成多段,V4 能一次處理全部。
Playground 上的實際使用案例
以下是一些人們已經在 Playground 上使用 DeepSeek V4 的方式:
開發者 會貼上程式碼並請 V4-Pro 進行審查、提出優化建議,或解釋不熟悉的程式模式。百萬字元的上下文容量意味著你可以放入整個模組——不僅僅是一個函式——並獲得考量完整脈絡的回饋。有些開發者會使用 V4-Flash 來解決快速語法問題,並使用 V4-Pro 進行架構層級的討論。
學生 使用 V4-Pro-Max 來處理數學與科學題組。「Think Max」推理模式會逐步講解證明過程,不僅有助於找到答案,也幫助理解解題思路。它同樣擅長以不同層次解釋概念——例如,請它向大一學生與博士候選人分別解釋梯度下降法,你會得到有意義地不同的回答。
研究人員 將 V4 輸入論文摘要或章節內容,並請求進行批判性分析、指出方法論缺口或連結相關研究。多語言訓練在這裡同樣有用——V4 能處理中文、日文或韓文的資料,並以英文討論而不失細微差異。
作家與行銷人員 使用 V4-Flash 進行發想、撰寫與編輯。它的速度足夠支援循環式創作——撰寫草稿、獲得回饋、修改再重複——不會像大型模型那樣因延遲而使互動變得令人沮喪。
在 Playground 上比較 DeepSeek V4 與其他模型
Playground 可讓你使用多家供應商的模型。以下是 V4 的定位:
在程式設計任務上,V4-Pro 是目前表現最佳的模型之一。它在 Codeforces 與 SWE-bench 上表現優於 Claude Opus 4.6,並且依任務類型與 GPT-5.4 不分上下。
在寫作和遵循指示方面,Claude 仍然略勝一籌。如果你需要細膩的文字或嚴格遵照複雜格式指示,Claude 模型往往更為可靠。
在一般知識與推理能力方面,V4-Pro、GPT-5.4 和 Gemini 3.1 Pro 的表現都相差僅幾個百分點。實際差異在大多數問題上幾乎察覺不到。
在日常任務的速度上,V4-Flash 幾乎無可匹敵。它反應快速,能力足以應付絕大多數日常問題。
Playground 的真正優勢在於你無需聽信他人。自行進行比較吧,所有模型都在那裡等著你。
常見問題
DeepSeek V4 在 Felo Playground 上真的免費嗎?
是的。V4-Pro 和 V4-Flash 均可免費使用。你不需要建立帳號或輸入付款資訊。
我需要安裝任何軟體嗎?
不需要。Felo LLM Playground 完全在瀏覽器中執行,網址為 playground.felo.ai。可在桌機與行動裝置上運作。
我可以在英文以外的語言中使用 DeepSeek V4 嗎?
可以。V4 在英文、中文、日文、韓文及許多其他語言上都有出色的表現。它的訓練重點之一就是多語言能力。
Felo Playground 與 Felo Search 有什麼不同?
Felo Search 結合了 AI 模型與即時網路搜尋,提供根據最新資訊的答案,並附上引用來源。Playground 則是直接的聊天介面 —— 沒有網路搜尋,只有你與模型互動。當你需要最新事實時請使用 Search;當你想要進行推理、撰寫程式、寫作或探索想法時,請使用 Playground。
有使用限制嗎?
Playground 可免費使用。在高流量時段可能會有特定速率限制,但一般使用並沒有代幣額度或每日上限。
立即體驗 DeepSeek V4
DeepSeek V4 已於 Felo LLM Playground 上線。開啟分頁、選擇模型,看看這個擁有兆級參數的開源模型能為你的工作帶來什麼可能。