How to Use OpenAI Reasoning Models: o1-preview/o1-Mini Models - Free AI Chat

Felo AI Chat now supports free use of the O1 Reasoning model
In the rapidly evolving landscape of artificial intelligence, OpenAI has introduced a groundbreaking series of large language models known as the o1 series. These models are designed to perform complex reasoning tasks, making them a powerful tool for developers and researchers alike. In this blog post, we will explore how to effectively use OpenAI's reasoning models, focusing on their capabilities, limitations, and best practices for implementation.
Felo AI Chat now supports free use of the O1 Reasoning model. Go give it a try!


Understanding the OpenAI o1 Series Models
The o1 series models are distinct from previous iterations of OpenAI's language models due to their unique training methodology. They utilize reinforcement learning to enhance their reasoning capabilities, allowing them to think critically before generating responses. This internal thought process enables the models to produce a long chain of reasoning, which is particularly beneficial for tackling complex problems.
Key Features of OpenAI o1 Models
1. **Advanced Reasoning**: The o1 models excel in scientific reasoning, achieving impressive results in competitive programming and academic benchmarks. For instance, they rank in the 89th percentile on Codeforces and have demonstrated PhD-level accuracy in subjects like physics, biology, and chemistry.
2. **Two Variants**: OpenAI offers two versions of the o1 models through their API:
- **o1-preview**: This is an early version designed for tackling hard problems using broad general knowledge.
- **o1-mini**: A faster and more cost-effective variant, particularly suited for coding, math, and science tasks that do not require extensive general knowledge.
3. **Context Window**: The o1 models come with a substantial context window of 128,000 tokens, allowing for extensive input and reasoning. However, it is crucial to manage this context effectively to avoid hitting token limits.
Getting Started with the OpenAI o1 Models
To begin using the o1 models, developers can access them through the chat completions endpoint of the OpenAI API.
Are you ready to elevate your AI interaction experience? Felo AI Chat now offers the opportunity to explore the cutting-edge O1 Reasoning model at no cost!
Go for a free trial of the o1 reasoning model.
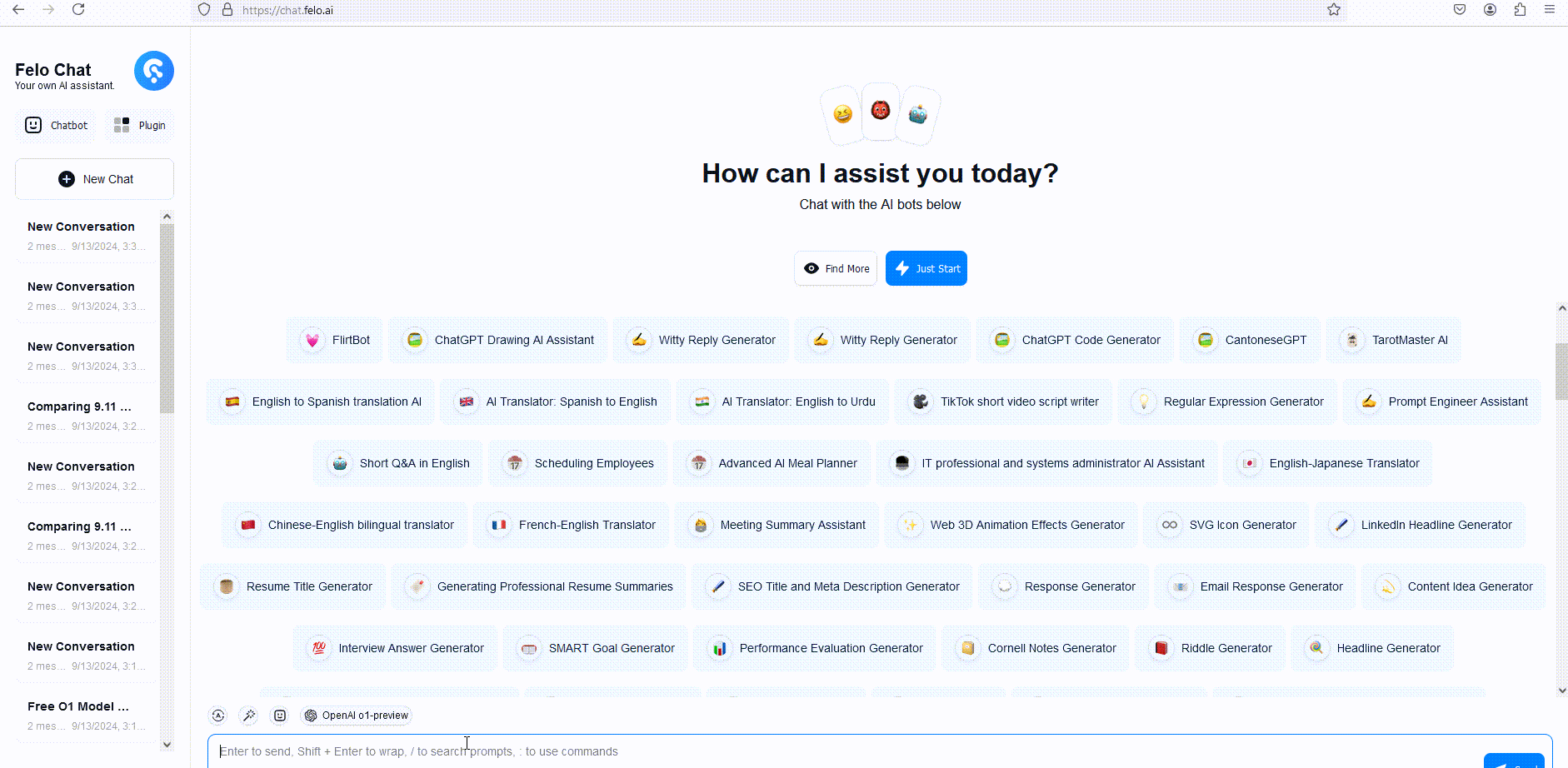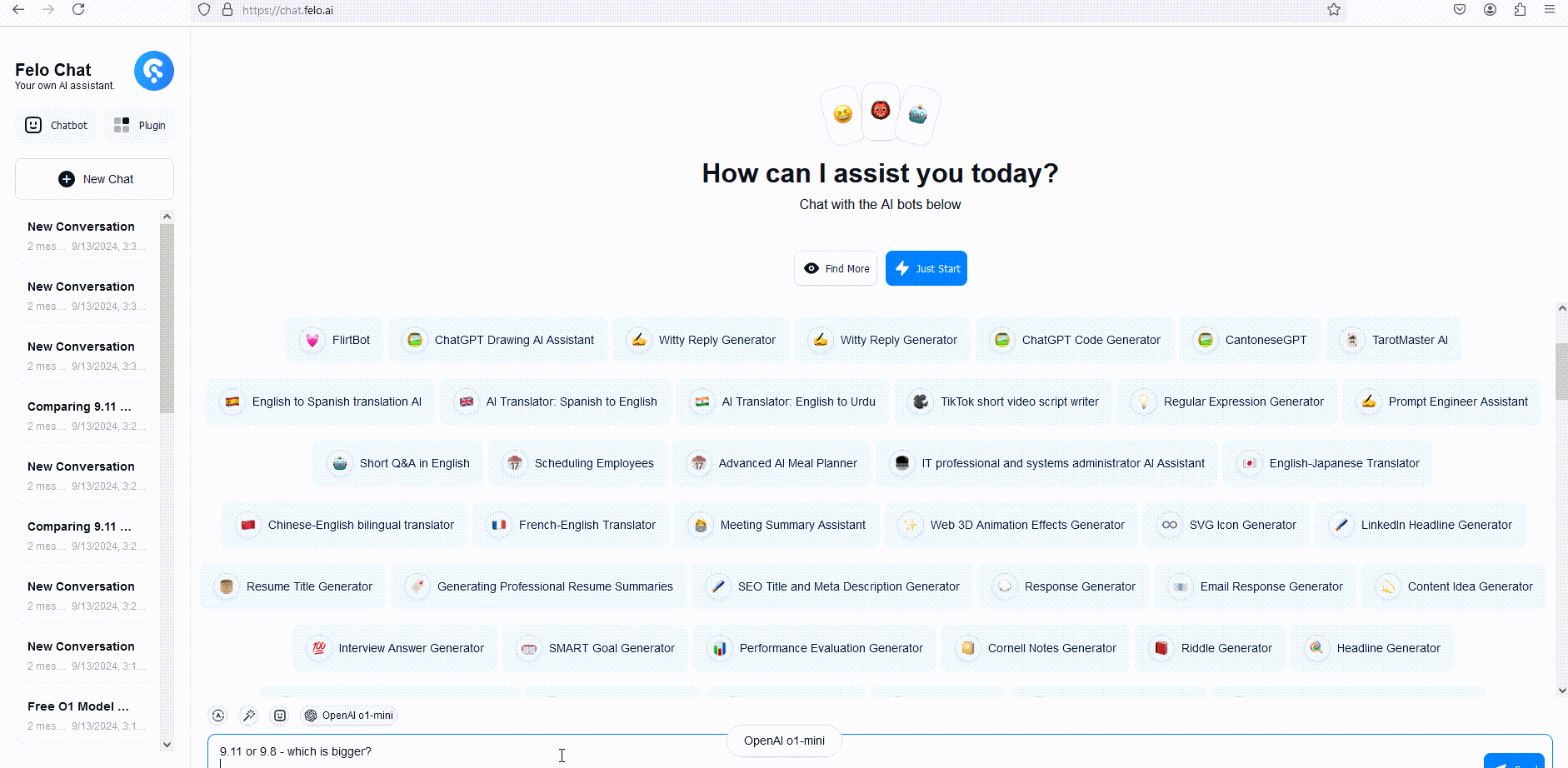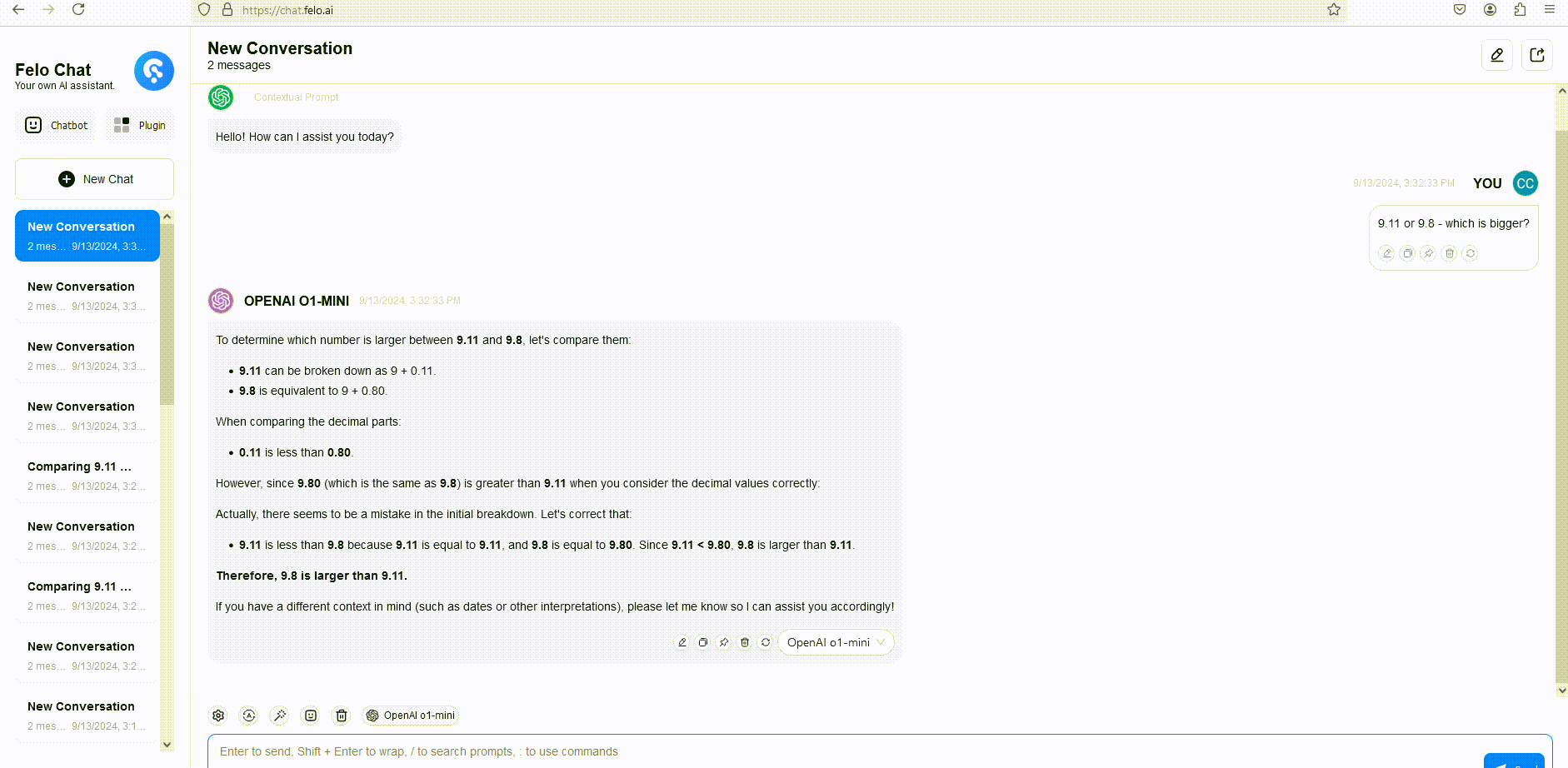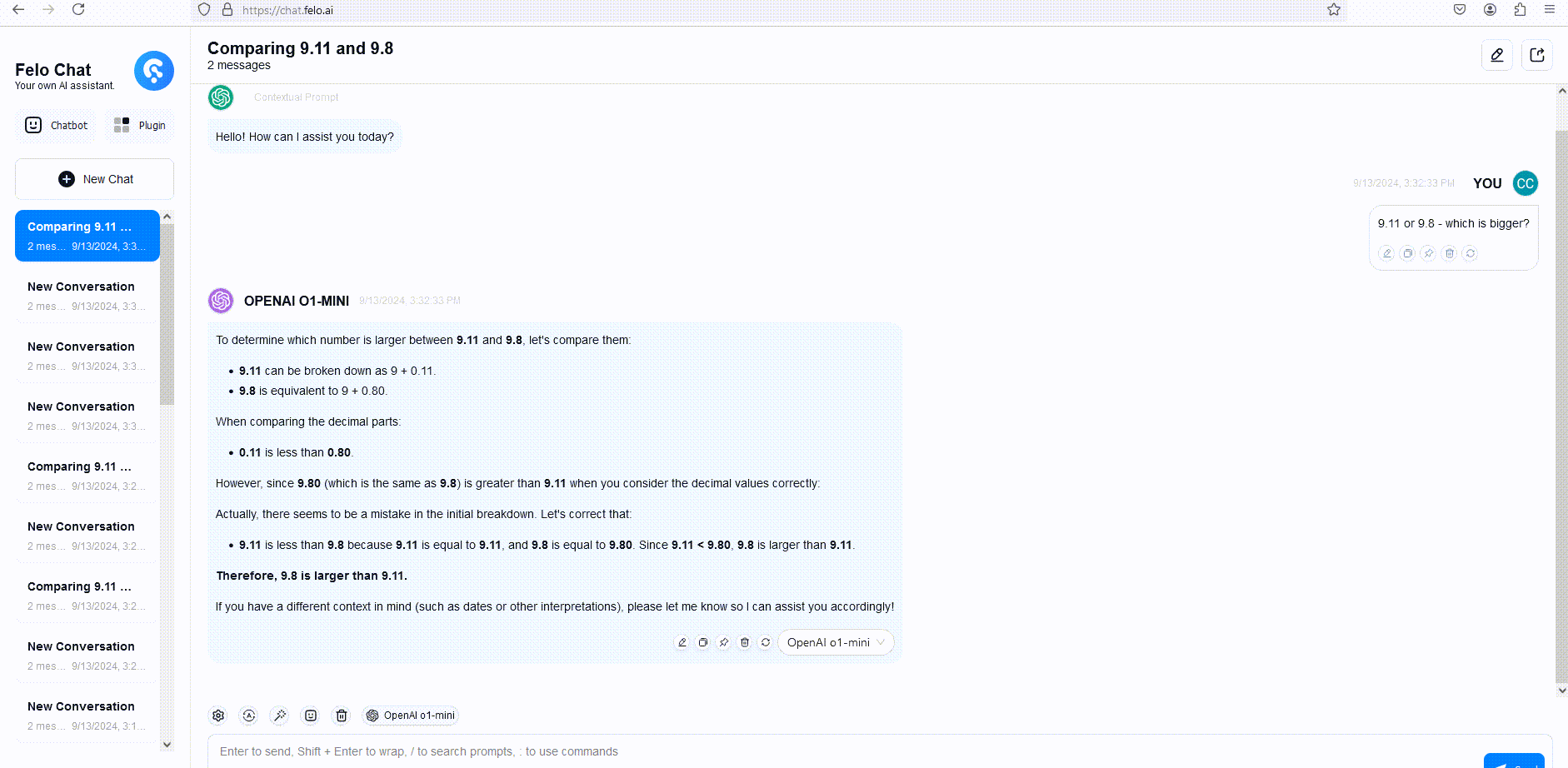
OpenAI o1 Models Beta Limitations
It’s important to note that the o1 models are currently in beta, which means there are some limitations to be aware of:
During the beta phase, many chat completion API parameters are not yet available. Most notably:
- Modalities: text only, images are not supported.
- Message types: user and assistant messages only, system messages are not supported.
- Streaming: not supported.
- Tools: tools, function calling, and response format parameters are not supported.
- Logprobs: not supported.
- Other:
temperature,top_pandnare fixed at1, whilepresence_penaltyandfrequency_penaltyare fixed at0. - Assistants and Batch: these models are not supported in the Assistants API or Batch API.
**Managing the Context Window**:
With a context window of 128,000 tokens, it’s essential to manage the space effectively. Each completion has a maximum output token limit, which includes both reasoning and visible completion tokens. For instance:
- **o1-preview**: Up to 32,768 tokens
- **o1-mini**: Up to 65,536 tokens
OpenAI o1 Models Speed
To illustrate, we compared the responses of GPT-4o, o1-mini, and o1-preview to a word reasoning question. Although GPT-4o provided an incorrect answer, both o1-mini and o1-preview answered correctly, with o1-mini arriving at the correct answer approximately 3-5 times faster.

How to choose between the GPT-4o, O1 Mini, and O1 Preview models?
**O1 Preview**: This is an early version of OpenAI O1 model, designed to leverage extensive general knowledge for reasoning through complex problems.
**O1 Mini**: A faster and more affordable version of O1, particularly good at coding, math, and science tasks, ideal for situations that don't require broad general knowledge.
The O1 models offer significant improvements in reasoning but are not intended to replace GPT-4o in all use cases.
For applications needing image input, function calls, or consistently quick response times, the GPT-4o and GPT-4o Mini models are still the best choices. However, if you're developing applications that require deep reasoning and can accommodate longer response times, the O1 models might be a great fit.
Tips for O1 Mini, and O1 Preview models Effective Prompting
OpenAI o1 Models work best with clear and straightforward prompts. Some techniques, such as few-shot prompting or asking the model to "think step by step," might not improve performance and can even hinder it. Here are some best practices to follow:
1. **Keep Prompts Simple and Direct**: The models are most effective when given brief, clear instructions without needing extensive elaboration.
2. **Avoid Chain-of-Thought Prompts**: Since these models handle reasoning internally, there's no need to prompt them to "think step by step" or "explain your reasoning."
3. **Use Delimiters for Clarity**: Employ delimiters like triple quotation marks, XML tags, or section titles to clearly define different parts of the input, which helps the model interpret each section correctly.
4. **Limit Additional Context in Retrieval-Augmented Generation (RAG)**: When supplying extra context or documents, include only the most pertinent information to avoid overcomplicating the model's response.
Prices for the o1 Mini and 1 Preview models.
The cost calculation for the o1 Mini and 1 Preview models is different from other models, as it includes an additional cost for reasoning tokens.
o1-mini Pricing
$3.00 / 1M input tokens
$12.00 / 1M output tokens
o1-preview Pricing
$15.00 / 1M input tokens
$60.00 / 1M output tokens
Managing o1-preview/ o1-mini Model Costs
To control expenses with the o1 series models, you can use the `max_completion_tokens` parameter to set a limit on the total number of tokens the model generates, encompassing both reasoning and completion tokens.
In earlier models, the `max_tokens` parameter managed both the number of tokens generated and the number of tokens visible to the user, which were always the same. However, with the o1 series, the total tokens generated can surpass the number of tokens shown to the user because of internal reasoning tokens.
Since some applications depend on `max_tokens` matching the number of tokens received from the API, the o1 series introduces `max_completion_tokens` to specifically control the total number of tokens produced by the model, including both reasoning and visible completion tokens. This explicit opt-in ensures that existing applications remain compatible with the new models. The `max_tokens` parameter continues to work as it did for all previous models.
Conclusion
OpenAI's o1 series models represent a significant advancement in the field of artificial intelligence, particularly in their ability to perform complex reasoning tasks. By understanding their capabilities, limitations, and best practices for usage, developers can harness the power of these models to create innovative applications. As OpenAI continues to refine and expand the o1 series, we can expect even more exciting developments in the realm of AI-driven reasoning. Whether you are a seasoned developer or just starting, the o1 models offer a unique opportunity to explore the future of intelligent systems. Happy coding!
Felo AI Chat always offers you a free experience with advanced AI models from around the world. Click here to give it a try!